the lite-ist stack: rails, sqlite, litestack, litestream, and fly
one of my favorite technologies is sqlite. it lets us build apps with fewer dependencies and less devops, which i love. you can run it in memory to create db-backed ruby scripts in a standalone file. i’m a fan of sqlite’s origin story (i started my career working for the navy and dod). i get an irrational kick out of being able to start a rails server in development without needing to also start a database server.
so, when i stumbled on litestack, i had to try it.
what’s litestack?
in a typical rails app we need a handful of other servers and processes:
- a database server (postgresql)
- a cache server (redis)
- a background job database (redis) and job processor (sidekiq)
- a pubsub queue (redis) and a “subscription adapter” that handles broadcasting and notifying subscribers (usually an in-process process rails provides)
litestack provides all of that in a single library, and backs the various storage needs by (unsurprisingly) sqlite databases. this let’s us skip a handful of architectural decisions, a fair bit of devops pain, and keeps our rails app that much simpler.
what should we build?
we need something that’ll put litestack through its paces. something that’ll lend itself to using the actioncable-y parts of hotwire. but, at the same time relatively simple and immediately understood by everyone.
we need a todo list app! the standard in blog-post-level technology testing. here’s what i have:
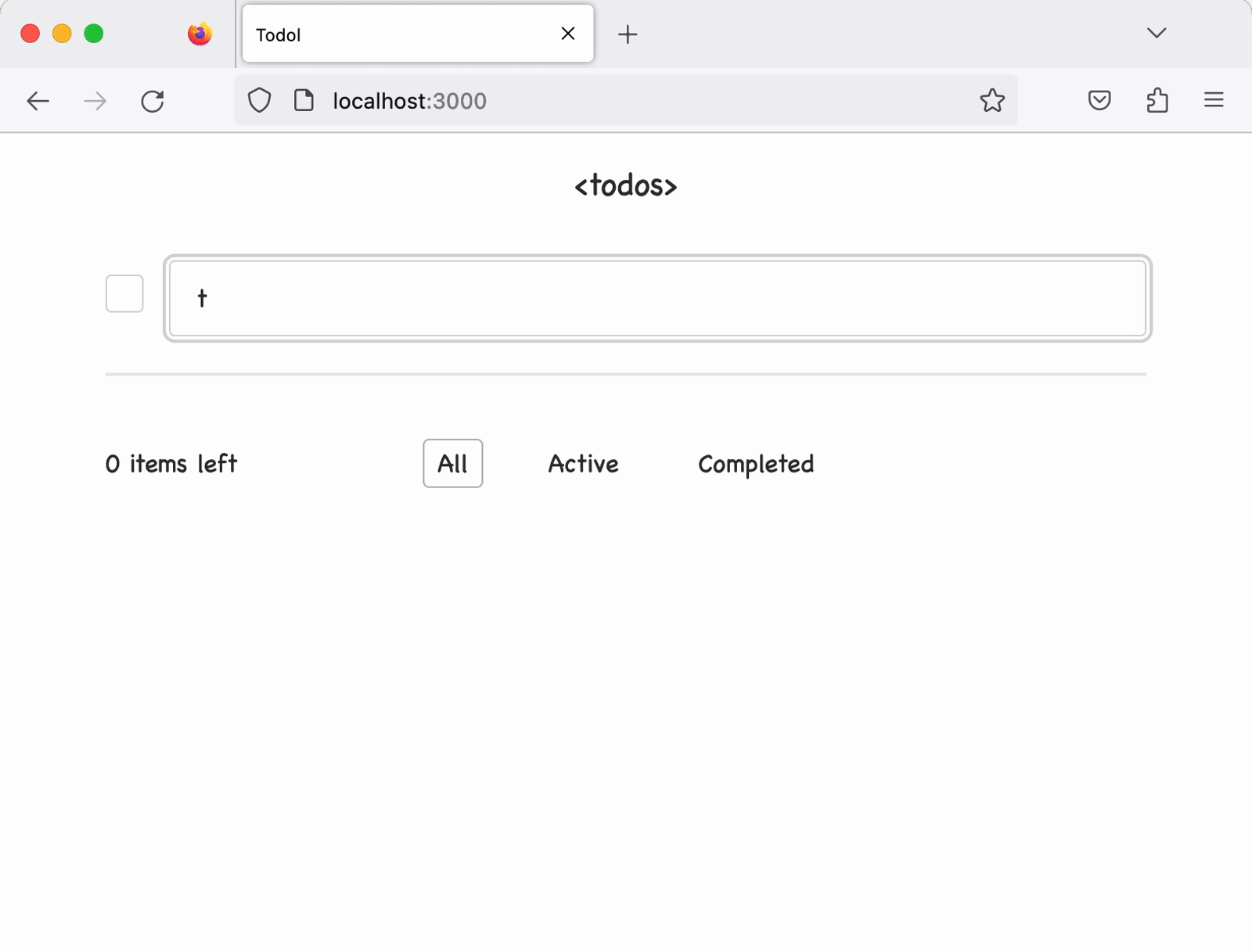
you can also see it live here: https://todol.fly.dev/.
as you can see, it’s very todomvc inspired. you can add todos, toggle them complete, filter your list of todos by completion status, it keeps a counter of items left updated, and – though it’s fairly forced usage of hotwire and actioncable – updates are reflected across browser tabs. but, forcing some hotwire usage will cause our app to enqueue jobs, process them, and broadcast on our pubsub queue.
some app code
i’m gonna skip over most of the application code, but i’ll call out a couple things that are relevant to testing litestack. otherwise, the code’s here.
the app db
todos are persisted with a user id that we store in your session. instead of a typical current_user controller method, we have a session_user method that either dumps a randomly generated user id in your session, or retrieves one that got set during a past request.
# db/migrate/20230522231531_adds_todos.rb
class AddsTodos < ActiveRecord::Migration[7.0]
def change
create_table :todos do |t|
t.string :session_user_id, null: false, index: true
t.string :title, null: false
t.boolean :completed, null: false, default: false
t.timestamps
end
end
end
# app/controllers/application_controller.rb
class ApplicationController < ActionController::Base
SessionUser = Data.define(:id) do
def todos
Todo.created_by(self)
end
end
private
def session_user
@session_user ||= SessionUser.new(id: session[:user_id] || generate_session_user_id)
end
helper_method :session_user
def generate_session_user_id
session[:user_id] = SecureRandom.hex
end
end
# app/controllers/todos_controller.rb
class TodosController < ApplicationController
before_action :find_todo, only: [:edit, :update, :destroy]
before_action :find_todos, only: [:index]
def create
@todo = session_user.todos.new(todo_params)
if @todo.save
# ... redacted ...
else
# ... redacted ...
end
end
# ... other actions ...
private
def find_todo
@todo = session_user.todos.find(params[:id])
end
def find_todos
@todos = session_user.todos.where(filtering? ? { completed: filtering?(:completed) } : nil)
end
# ... other helpers ...
end
so far, pretty standard rails crud-ing that covers using our application database.
background jobs and actioncable
the app has a single page, todos#index. all the mutation endpoints (create, update, update_many, destroy) return turbo_stream responses which update the index page.
for example, here’s create.turbo_stream.erb
<%# app/views/todos/create.turbo_stream.erb %>
<%= render partial: "todos/todo", locals: { todo: @todo } %>
<%= turbo_stream.replace(dom_id(Todo.new), partial: "todos/forms/new", locals: { todo: Todo.new }) %>
<%= turbo_stream.update("todos_left", todos_left) %>
our create response renders the turbo_stream actions needed to add or remove a todo from the page (handled by the todo partial), clear the new todo form, and update the counter of todos left. the update and destroy actions work the same way, they just don’t need to clear the form. update_many also works the same way, but it renders a todo partial for each todo that was updated.
having our controller respond with turbo_streams works for one browser tab. to get these updates happening across browser tabs, we tell the model to broadcast them, too:
# app/models/todo.rb
class Todo < ApplicationRecord
after_create_commit -> { broadcast_template_later(:create) }
after_update_commit -> { broadcast_template_later(:update) }
after_destroy_commit -> { broadcast_template_later(:destroy) }
# ... redacted ...
private
def broadcast_template_later(template)
broadcast_render_later_to(
session_user_id,
template: "todos/#{template}",
locals: { "@todo": self, todos_left: Todo.todos_left(session_user_id) }
)
end
end
lastly, we have to tell our user’s browser to subscribe to the channel we’re gonna send those updates on:
<%# app/views/todos/index.html.erb %>
<%= turbo_stream_from(session_user.id) %>
<%# ... redacted ... %>
at this point, our app is enqueuing and processing background jobs that render turbo_stream responses, then broadcasting those rendered responses over actioncable’s pubsub queue.
caching
we’re skipping it. litestack will make it so our rails cache is backed by sqlite, too, but our app isn’t doing anything to leverage the cache. we will still ensure litestack’s managing our cache database, though.
installing and configuring litestack
installing can be as simple as adding litestack to your gemfile and editing config/database.yml, config/cable.yml, and config/environments/production.rb.
then, you can optionally configure litestack using config/litejob.yml, config/litecable.yml, and the second parameter of config.cache_store =.
but i don’t like that default setup. i want my config files to match the environment-ified structure of database.yml, which litestack doesn’t support out-of-the-box. i also want all my litestack database files to live beside my application database in the db folder.
let’s start with the base setup, then i’ll walk you through the things i’ve further configured to better matched my tastes.
base setup
at a minimum, we have to install the gem:
# Gemfile
gem "litestack"
tell rails to use litestack for our application db:
# config/database.yml
default: &default
- adapter: sqlite
+ adapter: litedb
tell rails to use litestack for actioncable:
# config/cable.yml
development:
- adapter: redis
- url: redis://localhost:6379/1
+ adapter: litecable
test:
adapter: test
production:
- adapter: redis
- url: redis://localhost:6379/1
+ adapter: litecable
channel_prefix: todol_production
tell rails to use litestack for actionjob and caching:
# config/environments/production.rb
config.active_job.queue_adapter = :litejob
config.cache_store = :litecache
that’s it! add a gem, make a few config file changes, and you’ve sqlited all the typical rails dependencies. beautiful 😍 but let’s keep going.
configuring litecache
this one’s probably the most straightforward. rails lets you set the cache_store using the config.cache_store= method. the first parameter is an identifier of the store and the second parameter is a hash of options that gets forwarded on to that cache store’s constructor.
add the following to config/environments/production.rb:
# config/environments/production.rb
config.cache_store = :litecache, YAML.load_file(Rails.root.join("config/litecache.yml"), aliases: true).
fetch(Rails.env, {}).
symbolize_keys
optionally, you can do development, too. i did, but it’s also pretty common to use memory caching in development and real caching in production.
# config/environments/development.rb
# ... leave all the other caching config in place, just add this somewhere after ...
if Rails.root.join("tmp/caching-dev.txt").exist?
config.cache_store = :litecache, YAML.load_file(Rails.root.join("config/litecache.yml"), aliases: true).
fetch(Rails.env, {}).
symbolize_keys
end
lastly, add the litecache.yml configuration file in your config folder:
# config/litecache.yml
default: &default
config_path:
sync: 1
development:
<<: *default
path: db/development_litecache.sqlite3
test:
<<: *default
path: db/test_litecache.sqlite3
production:
<<: *default
path: db/production_litecache.sqlite3
nil-ing the config_path
in litestack, options flow through an inheritance chain of class-level constants, methods that merge constants to loaded configuration files, and ultimately here: https://github.com/oldmoe/litestack/blob/master/lib/litestack/litesupport.rb#L241.
the environment-based setup we’re doing now configures litestack using a mix of configuration option arguments, changing litestack defined constants, and setting instance variables litestack uses. since we’re setting configuration options ourselves, we don’t want any other config files loaded, so we set config_path equal to nil.
this isn’t actually necessary in the litecache.yml file since nothing in litestack loads a config/litecache.yml file, but it is in the others.
we’re changing the structure of config/litejob.yml litestack expects. if we don’t also tell litestack “hey don’t bother loading that config file” we’re gonna have a bad time.
sync levels
when you connect to a sqlite database, you can specify a synchronous level. tl;dr - this give us some control over when the sqlite library commits changes to our database file, and we can trade speed for less resiliency of our database file. details here: https://www.sqlite.org/pragma.html#pragma_synchronous.
for litestack, the cache db’s default is sync: 0 – maximum speed, minimum resiliency. litestack’s general default is sync: 1, which should be good enough for most apps. i don’t know if it’s strictly necessary, but i kinda think if we’re gonna backup the database so it survives container restarts (spoiler! 🚨), it makes sense to set it to sync: 1.
configuring litejob and litecable
it’s the same idea, but we don’t have quite as convenient a spot to load our config file. so we’ll do some monkey patching, instead.
first, tell bundler we’ll require litestack ourselves.
# Gemfile
gem "litestack", require: false
second, add the monkey patches. you can put this file anywhere, but i like lib/:application_name/patches/litestack.rb:
# lib/todol/patches/litestack.rb
module ActiveJob
module QueueAdapters
class LitejobAdapter
class Job
@options = YAML.load_file(Rails.root.join("config/litejob.yml"), aliases: true).
fetch(Rails.env, {}).
symbolize_keys
end
end
end
end
require "litestack"
if defined?(ActionCable::SubscriptionAdapter::Litecable)
module ActionCable
module SubscriptionAdapter
class Litecable < ::Litecable
DEFAULT_OPTIONS.merge!(
YAML.load_file(Rails.root.join("config/litecable.yml"), aliases: true).
fetch(Rails.env, {}).
symbolize_keys
)
end
end
end
end
we’re using the same pattern to load the config file, but in litejob we set a class-level instance variable in ActiveJob::QueueAdapters::LitejobAdapter::Job, before we require litestack. this is because litestack creates and configures the connection to the job queue when it’s required. so to set the options using our config fle, we have to skate to where the puck’s gonna be, so to speak, and that’s the @options variable.
in litecable we can just…change a…uh…“constant”…after litestack's loaded 😅 you gotta love ruby, lol!
next, add the config files:
# config/litejob.yml
default: &default
config_path:
logger: # use actionjob's logging (ref: https://github.com/oldmoe/litestack/blob/master/lib/active_job/queue_adapters/litejob_adapter.rb#L36)
sync: 1
development:
<<: *default
path: db/development_litejob.sqlite3
test:
<<: *default
path: db/test_litejob.sqlite3
production:
<<: *default
path: db/production_litejob.sqlite3
# config/litecable.yml
default: &default
config_path:
development:
<<: *default
path: db/development_litecable.sqlite3
test:
<<: *default
path: db/test_litecable.sqlite3
production:
<<: *default
path: db/production_litecable.sqlite3
lastly, make sure our app requires this file. add this at the bottom of config/application.rb:
# config/application.rb
# ... redacted ...
require "todol/patches/litestack"
if the patching and off-the-rails configuration gives you too much heartburn, you really can just use litestack more as it intended with non-environment-ified config files. but, if you’re like me, the symmetry of having all your config files match database.yml is worth a patch or two.
either way, at this point, we’re good to go! we can use rails like we’re used to with all the things sqlited. but no application’s complete until we can deploy it.
fly.io and litestream
litestream is absolute wizardry that lets us continually backup a sqlite database to s3, and restore our database from that backup. in a world of containerized / ephemeral deployment platforms, it’s ushering in a sqlite renaissance.
fly.io is one such deployment platform, but critically they’re the one backing litestream.
they also try to make it easy to get started with rails. you can install their cli, and run fly launch in your rails app, and it’ll autogenerate all the files you need, including a dockerfile.
i’ll leave getting started with fly.io and creating an aws account and s3 bucket for litestream as exercises for the reader, but assuming you’ve made it through both, here’s the changes you need to backup your litestack databases with litestream.
one more config file
litestream needs a config file to stream more than one database, and we have three. we want litestream to backup up our application database, our job queue database, and our cache database. add a config/litestream.yml file with the following:
dbs:
- path: /app/db/production.sqlite3
replicas:
- url: s3://:bucket/:prefix/production.sqlite3
- path: /app/db/production_litecache.sqlite3
replicas:
- url: s3://:bucket/:prefix/production_litecache.sqlite3
- path: /app/db/production_litejob.sqlite3
replicas:
- url: s3://:bucket/:prefix/production_litejob.sqlite3
you’ll have to replace :bucket and :prefix with your own values.
installing and running litestream in your dockerfile
somewhere in your dockerfile, run these two commands to install it and drop the executable on your path:
ADD https://github.com/benbjohnson/litestream/releases/download/v0.3.9/litestream-v0.3.9-linux-amd64-static.tar.gz /tmp/litestream.tar.gz
RUN tar -C /usr/local/bin -xzf /tmp/litestream.tar.gz
change your cmd to restore your databases, migrate your app db, and run your rails app through litestream:
CMD \
litestream restore -v -if-db-not-exists -if-replica-exists -o /app/db/production.sqlite3 "s3://:bucket/:prefix/production.sqlite3" \
&& litestream restore -v -if-db-not-exists -if-replica-exists -o /app/db/production_litecache.sqlite3 "s3://:bucket/:prefix/production_litecache.sqlite3" \
&& litestream restore -v -if-db-not-exists -if-replica-exists -o /app/db/production_litejob.sqlite3 "s3://:bucket/:prefix/production_litejob.sqlite3" \
&& ./bin/rails db:migrate \
&& litestream replicate -exec "./bin/rails server -p ${PORT}" -config ./config/litestream.yml
store your litestream secrets with fly
$ fly secrets set LITESTREAM_ACCESS_KEY_ID="$AWS_ACCESS_KEY_ID" LITESTREAM_SECRET_ACCESS_KEY="$AWS_SECRET_ACCESS_KEY"
scaling fly to zero
“scale-to-zero” means when our application isn’t being used, we turn it all the way off. this makes it cheaper for us to run. we can get fly to do this for us with a little effort.
running fly launch should create a fly.toml file. in there we want to make sure our [http_service] is configured to auto stop. this should happen by default, but just in case, you need to make sure you have at least this much set:
[http_service]
auto_stop_machines = true
auto_start_machines = true
min_machines_running = 0
then sometime after you’ve deployed the app, run the following cli commands:
$ fly scale count 1
$ fly machines list
$ machine update $machine_id_from_list_command --restart no
conclusion
as a fan of sqlite and simplified rails apps, i love it!
there are downsides. everything has to run on one box – i.e. to horizontally scale, you have to replace each service with a suitable server-based alternative. you’re running your job processor in-band with your web server – i.e. it taxes your ability to serve user’s web requests. deploying is going to come with a second of downtime.
the upside is extreme simplicity! extreme cost effectiveness. it’s super lite, but maybe heavyweight enough for your next project.